
Dans ce deuxième article sur le réseau dans Kubernetes, nous allons voir le fonctionnement des services. Nous reviendrons sur les concepts essentiels du premier article et je vous parlerai particulièrement du composant Kube Proxy.
Rappel du besoin
Les containers sont des instances d'images dites immuables. Normalement, une image est lancée et ne doit pas être modifiée. Chaque modification de l'image passe par un nouveau container, cela permet de réaliser un véritable versionning des workloads. Lorsque l'on souhaite modifier la configuration d'un container, on en crée un nouveau avec la même image et de nouveaux paramètres qui peuvent être insérés sous plusieurs formes (variables d'environnement, ConfigMap, etc...)
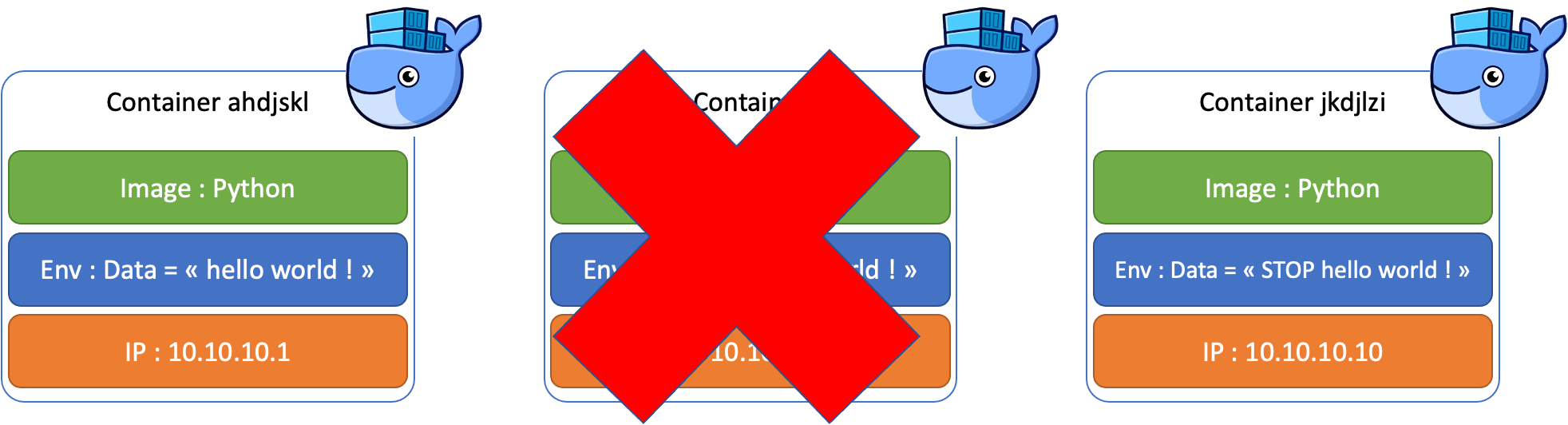
Sous Kubernetes, les containers sont inclus dans un Pod.
Nous avons vu qu'une adresse IP est assignée à un Pod lors de son démarrage par l'intermédiaire de l'IPAM de la CNI (Container Network Interface) qui est un plugin du composant Kubelet (je reviendrai sur ces deux composants dans des articles dédiés).
Donc un Pod change d'adresse IP chaque fois qu'il est mis à jour (en fait c'est un nouveau Pod).
Il est nécessaire de trouver un moyen d'assigner une adresse IP durable pour un composant intermédiaire sur lequel la résolution DNS pourra être faite.
Les services Kubernetes permettent de répondre à ce besoin. De plus ils assurent le Load Balancing entre plusieurs Pods répliqués.
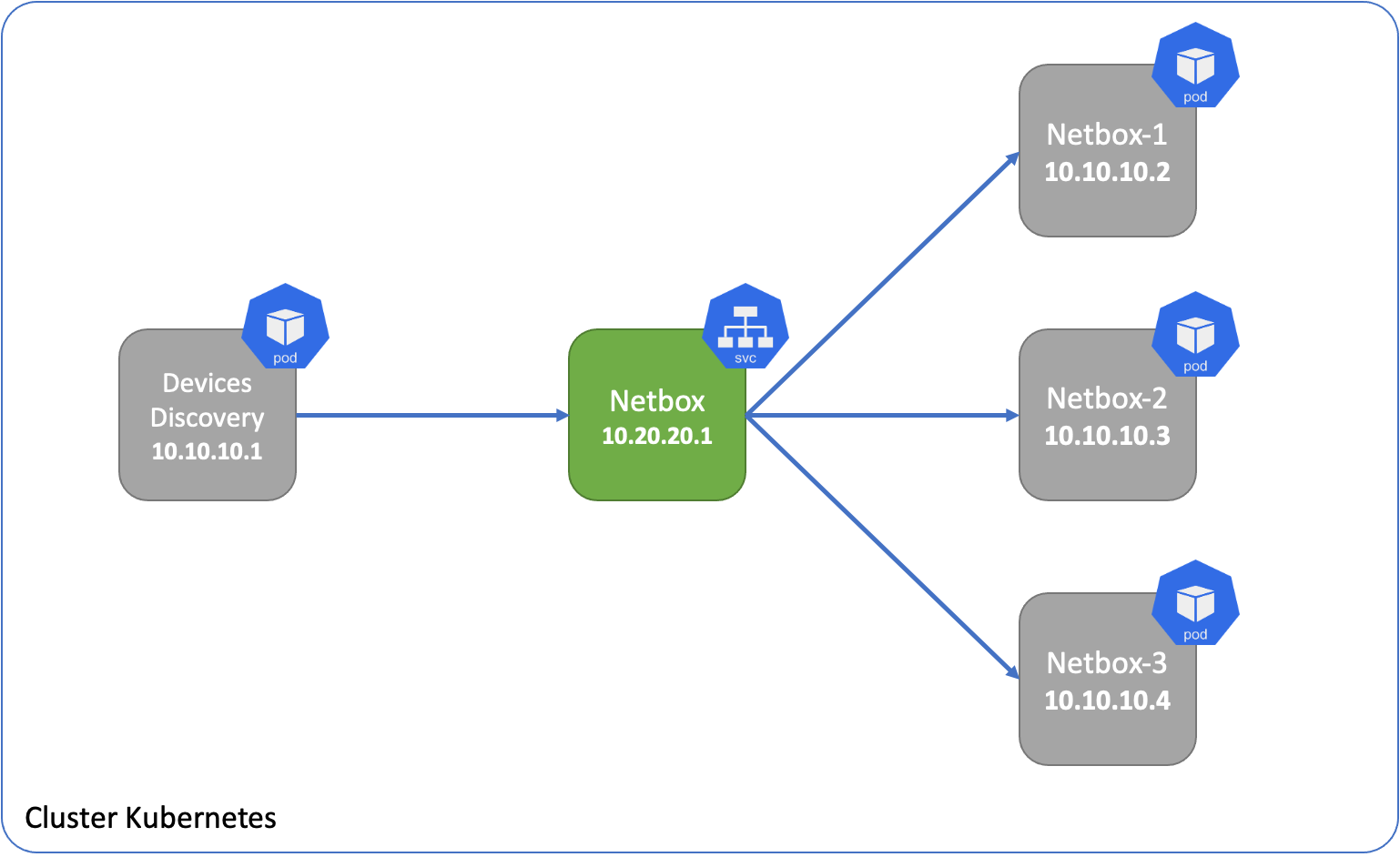
Rentrons dans les détails.
Services Kubernetes
Lors de la création d'un service, un paramètre "selector" est configuré pour lui permettre de connaitre les Pods qu'il doit servir. Ce selector est représenté par un label.
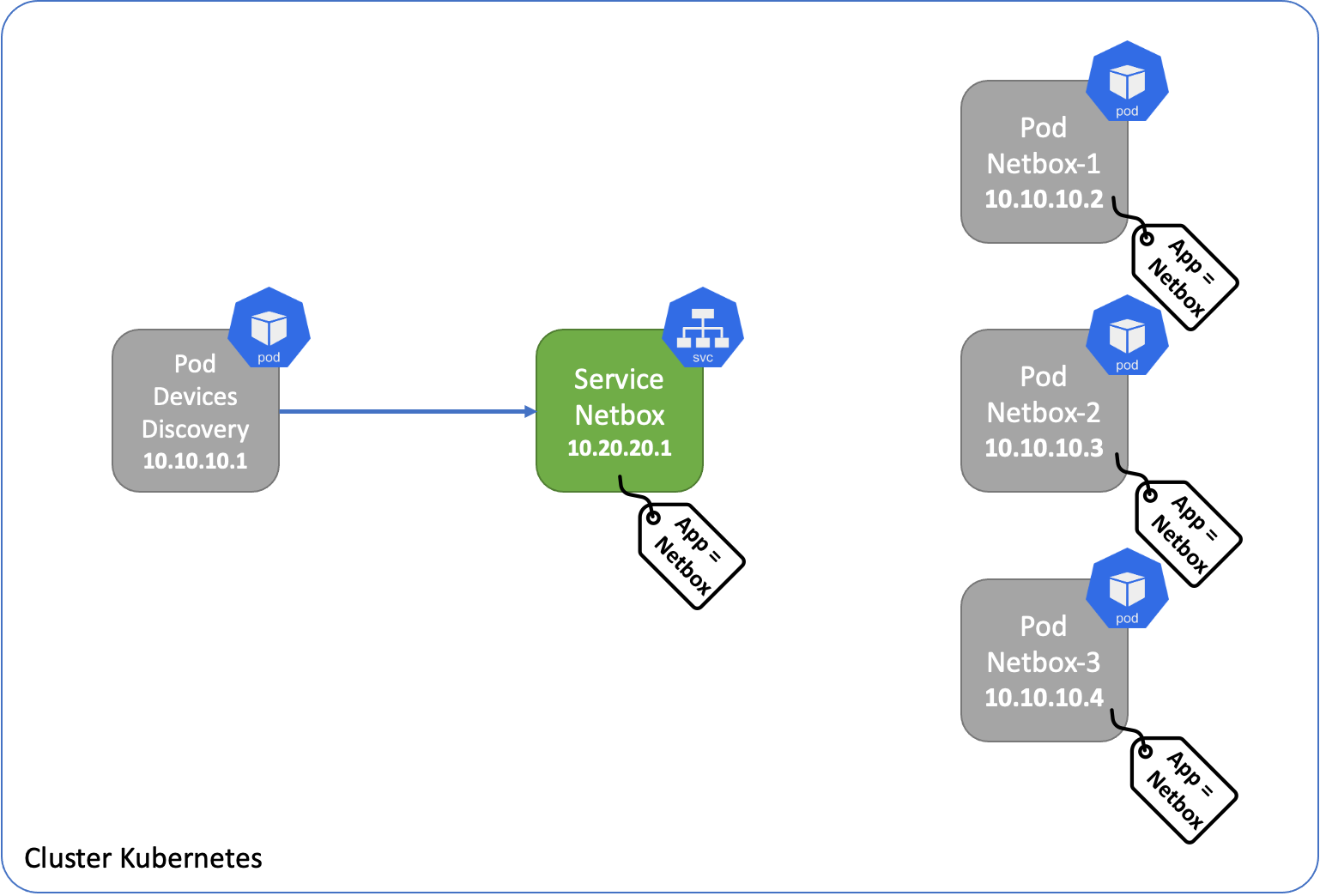
Pour chaque Pod possédant ce selector comme attribut, un autre composant de Kubernetes est créé : un Endpoints.
Endpoints
Le Endpoints controller gère la création et la maintenance des endpoints pour savoir quand un Pod configuré avec le selector concerné est ajouté, supprimé, disponible ou non. Ainsi le service se base sur les Endpoints pour connaitre les Pods à servir.
Il existe deux listes d'adresses/ports dans un endpoint:
- addresses : seules les adresses qui ont passé les tests "pod readiness checks" apparaissent dans cette liste
- not ready addresses : les adresses qui n'ont pas réussi à passer les tests
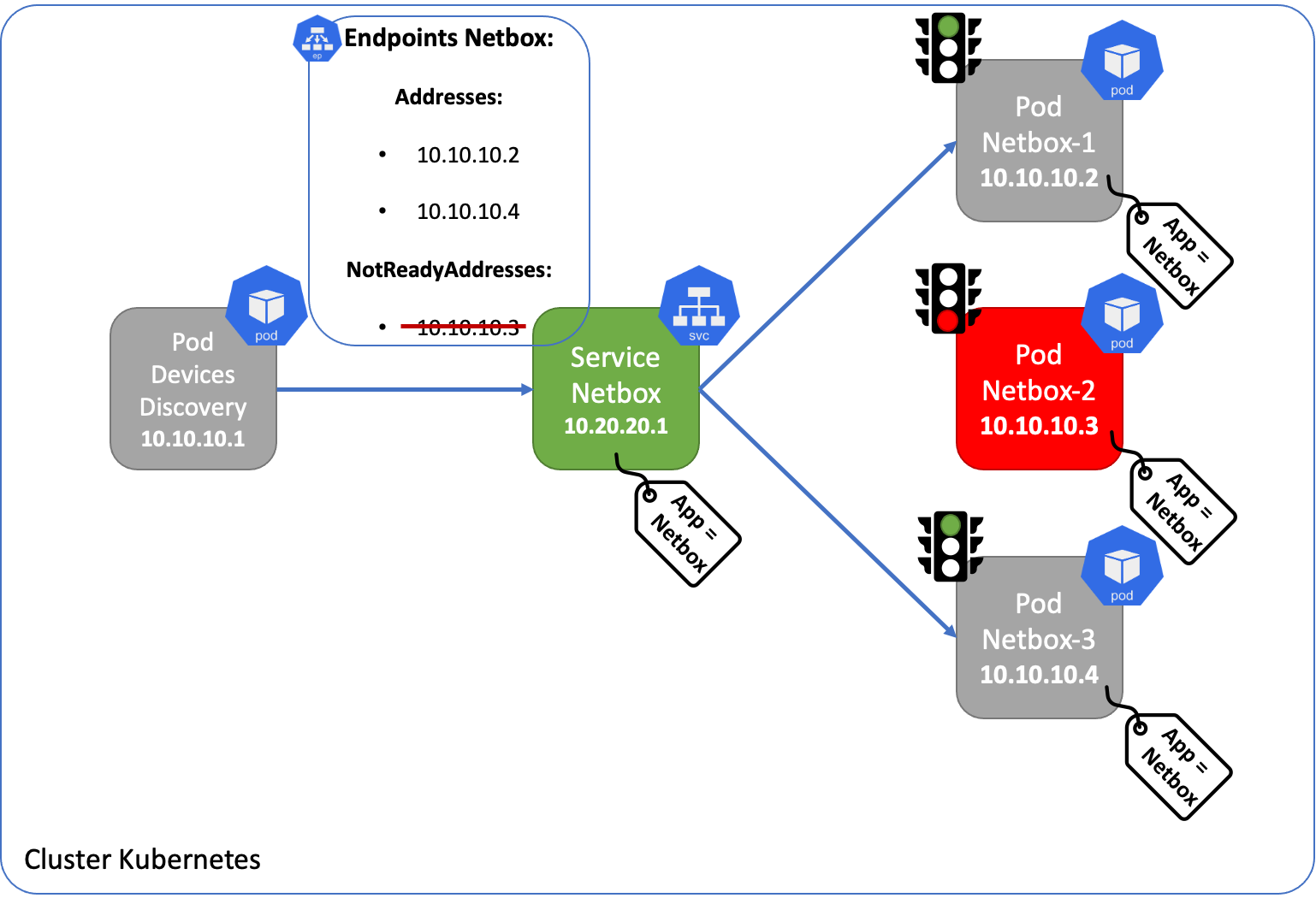
Kube Proxy, que nous détaillerons plus loin dans cet article, surveille les services et les endpoints pour mettre à jour, en conséquence, les règles de routage sur l'host Linux (Node) qui permettent la communication vers les Services.
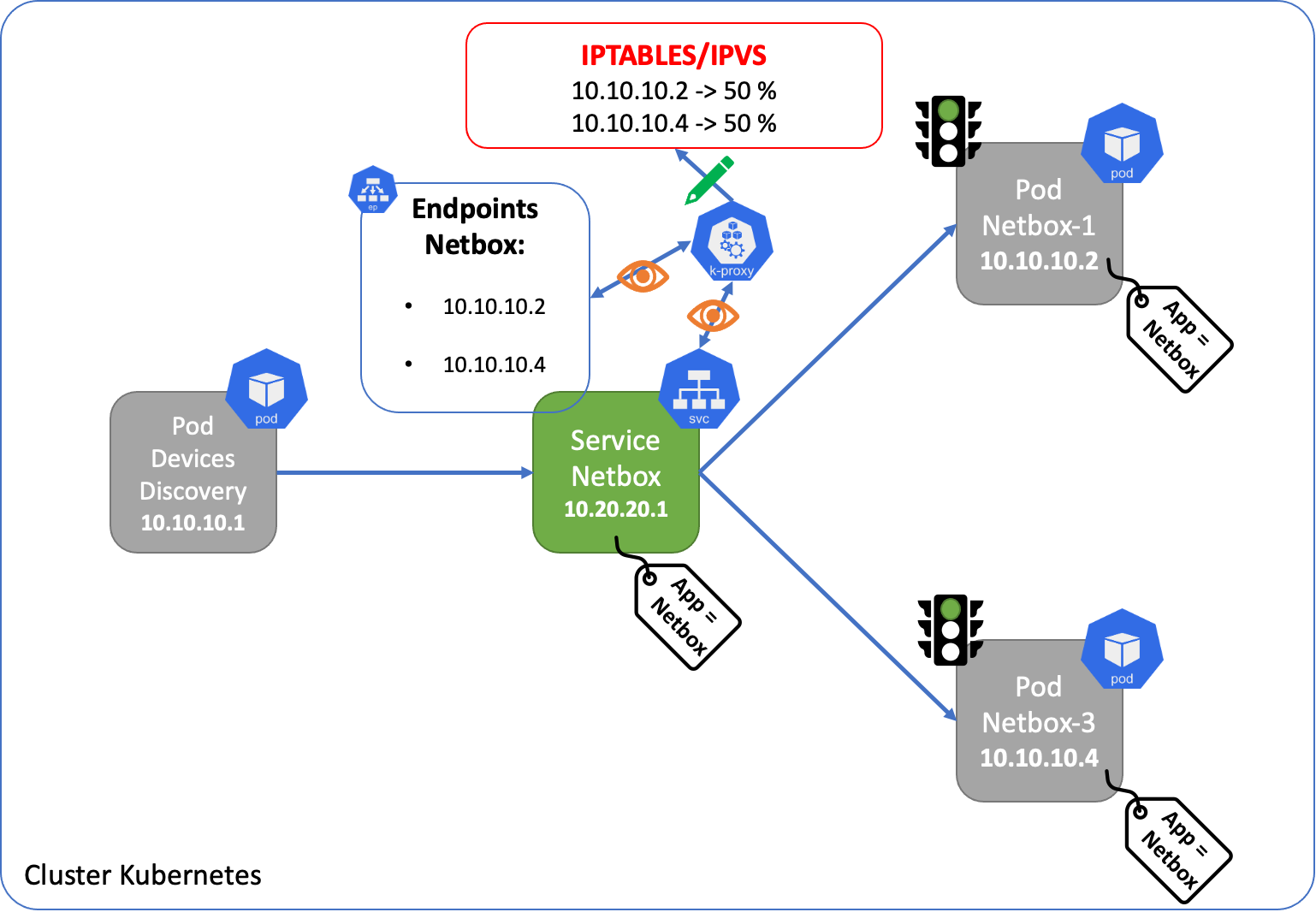
Kube Proxy
Kube Proxy est le composant responsable des Services Kubernetes. Il tourne sur chacun des Nodes du Cluster et permet de configurer les règles de load balancing au niveau de l'host linux pour les protocoles UDP, TCP et SCTP. Il existe plusieurs modes d'exécution dont les 3 suivants :
- userspace
- iptables
- ipvs
User Space mode
Dans ce mode, pour chaque connexion d'un client local vers un service, le flux passe par le Kernel via iptables, puis remonte dans le User Space via Kube Proxy pour être Load Balancé vers les Pods concernés.
Ce mode a été déclaré obsolète, car il était considéré comme mécanisme trop lent lié à la création d'un goulet d'étranglement et aux allers retours entre le User Space et le Kernel.
iptables mode
Iptables est un utilitaire de Firewall Linux très connu qui permet de faire du filtrage et du NAT sur les paquets entrant dans le Kernel. Cela est rendu possible grâce à son interfaçage avec le module netfilter du Kernel Linux qui permet d'intercepter et de modifier les paquets. Si vous n'êtes pas familier avec netfilter, voici un très bon article de Justin Ellingwood dans un tutoriel de Digital Ocean. Avec ce mode, les flux passent uniquement par iptables qui effectue, lui-même, le Load Balancing vers les pods concernés.
Cependant, la façon dont kube-proxy programme les règles iptables, implique un algorithme nominale de style O(n), où n croît à peu près proportionnellement avec la taille du cluster (plus précisément avec le nombre de services et le nombre de pods backend derrière chaque service)
IPVS (IP Virtual Server) mode
IPVS est une fonctionnalité du noyau Linux spécialement conçue pour l'équilibrage de charge. En mode IPVS, kube-proxy programme le load balancer IPVS au lieu d'utiliser iptables.
IPVS possède une API et une routine de recherche optimisée basée sur du Hashing plutôt que sur une liste de règles séquentielles (Chains). Cela résulte sur un traitement de connexion de kube-proxy avec une complexité de calcul nominale de O(1). En d'autres termes, dans la plupart des scénarios, ses performances de traitement de connexion resteront constantes indépendamment de la taille du cluster.
De plus, en tant que Load Balancer dédié, IPVS dispose de plusieurs algorithmes de planification différents tels que le round-robin, le délai le plus court attendu, le moins de connexions et diverses approches de hachage. Alors qu'avec iptables, kube-proxy utilise un algorithme de sélection aléatoire à coût égal.
Un inconvénient potentiel d'IPVS est que les paquets empruntent un chemin, à travers les filter hooks d'iptables, très différent des paquets traités dans des circonstances normales.
Cela dit, vous l'aurez compris, IPVS sera plus rapide et efficace dans le Load Balancing qu'iptables.
Pour plus de détails sur les modes de fonctionnement de Kube-Proxy, voici un très bon article de Arthur Chiao Cracking Kubernetes Node Proxy (aka kube-proxy).
Dans le prochain article, nous aborderons les différent type de services que l'on trouve dans Kubernetes.
